Amlsec - Automated Security Risk Identification Using AutomationML-based Engineering Data

This prototype identifies security risk sources (i.e., threats and vulnerabilities) and types of attack consequences based on AutomationML (AML) artifacts. The results of the risk identification process can be used to generate cyber-physical attack graphs, which model multistage cyber attacks that potentially lead to physical damage.
- Build AML2OWL
This prototype depends on a forked version of the implementation of the bidirectional translation between AML and OWL for the ETFA 2019 paper "Interpreting OWL Complex Classes in AutomationML based on Bidirectional Translation" by Hua and Hein. Clone the repository, compile the projects, and assemble an application bundle of aml_owl:
$ cd aml_models
$ mvn clean compile install
$ cd ../aml_io
$ mvn clean compile install
$ cd ../aml_owl
$ mvn clean compile install assembly:single
- Setup the AMLsec Base Directory
Clone this repository, create the application base directory (usually located in the user's home directory), and place the files located in amlsec-base-dir and the assembled AML2OWL JAR (located in aml_owl/target/) there. The AMLsec base directory and the path to the AML2OWL JAR must be set in the configuration file using the keys baseDir and amlToOwlProgram, respectively.
- Setup Apache Jena Fuseki
Install and start Apache Jena Fuseki:
$ java -jar <path_to_apache-jena-fuseki-X.Y.Z>/fuseki-server.jar --update
- Build AMLsec
Finally, build and start the app by using sbt.
$ sbt "runMain org.sba_research.worker.Main"
Usage
The implemented method utilizes a semantic information mapping mechanism realized by means of AML libraries. These AML security extension libraries can be easily reused in engineering projects by importing them into AML files.
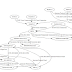
The capabilities of this prototype are demonstrated in a case study. Running this prototype as is will yield the knowledge base (can be accessed via Fuseki), which also includes the results of the risk identification process, and the following pruned cyber-physical attack graph:

The prototype utilizes the Akka framework and is able to distribute the risk identification workload among multiple nodes. The Akka distributed workers sample was used as a template.
To run the cluster with multiple nodes:
- Start Cassandra:
$ sbt "runMain org.sba_research.worker.Main cassandra"
- Start the first seed node:
$ sbt "runMain org.sba_research.worker.Main 2551"
- Start a front-end node:
$ sbt "runMain org.sba_research.worker.Main 3001"
- Start a worker node (the second parameter denotes the number of worker actors, e.g., 3):
$ sbt "runMain org.sba_research.worker.Main 5001 3"
If you run the nodes on separate machines, you will have to adapt the Akka settings in the configuration file.
Performance Assessment
The measurements and log files obtained during the performance assessment are available upon request.
 Reviewed by Zion3R
on
5:30 PM
Rating:
Reviewed by Zion3R
on
5:30 PM
Rating:



